
انسانهایی وجود دارند که علاقه به پیشرفت ندارند، اغلب تمایل دارند خود را بهترین موجودات و یا بهتر از بهترینها بدانند و از آن لذت می برند. اما خلاف این هم وجود دارد، عده ای می دانند که تکامل یک مسیر بی انتهاست و پایانی برای آن نیست. یکی از اشکالاتی که در انسانها وجود دارد سرعت پایین پردازش و نمونه برداری مغز است. به عنوان مثال به پره های پنکه در حال چرخش دقت کنید، وقتی سرعت چرخش از حدی بالاتر می رود دیگر مغز توانایی تحلیل آن را ندارد و فکر می کند پره ها ثابت شدند و این در حالیست که فضای پشت پره های پنکه به خوبی دیده می شود. اما اگر سرعت باز هم افزایش پیدا کند علاوه بر اینکه پره ها ثابت نیستند مغز برداشت اشتباه از چرخش معکوس خواهد داشت. در مثالی دیگر، کنترل موتور سیکلت در شهر با سرعت بالا، تقریبا ناممکن است، زیرا مغز نمی تواند رفتار پیرامون خود با بیش از نرخ از پیش تعیین شده را، ارزیابی کند و یا از حادثه ای جلوگیری کند. این نشان می دهد سرعت پردازش مغز تا نرخ نمونه برداری معینی تعریف شده است و بیش از آن توانایی تحلیل را ندارد.
یادگیری عمیق به تازگی به منظور تشریح مفهوم از تصاویر مورد استفاده قرار می گیرد. علاوه بر اینکه به کمک یادگری عمیق می توان مفهوم کلی از تصاویر را استخراج کرد، می توان به گونه ای دیگر، مفهوم جزیی از تصاویر را استخراج و طبقه بندی کرد. با طبقه بندی جزیی می توان دست یافت که چه چیزی در کجای تصویر قرار دارد. از این روشهای محلی می توان به (الف) R-CNN، (ب) RPN، (ج) Fast R-CNN، (د)Faster R-CNN و (ه) YOLO اشاره کرد.
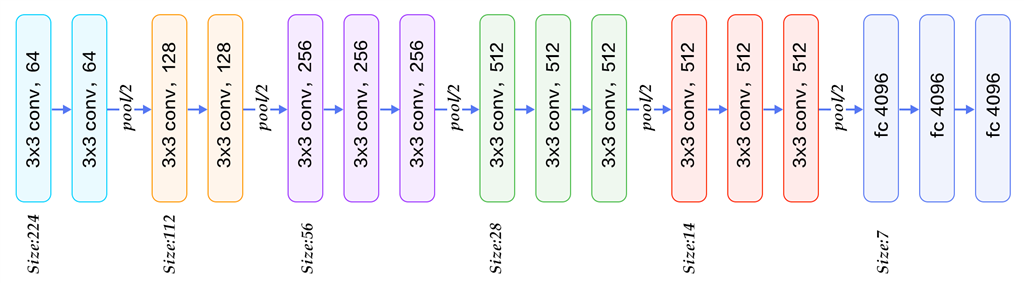
سرعت طبقه بندی در روش Fast R-CNN حدود 1 فریم در هر 2 ثانیه است که با 25 برابر سریعتر از R-CNN است. زیسرمن در روشی برای یادگیری عمیق، مدلهایی خیلی عمیق با 5 لایه کانولوشن ارائه کرد، که این مدل ها اعم از 11 لایه وزنی،13 لایه وزنی، 16 لایه وزنی، و 19 لایه وزنی است که سرعت Faster R-CNN با مدل 16 لایه ای زیسرمن، 7 فریم در ثانیه، حدود 200 برابر از R-CNN است . مدل 16 لایه وزنی به شرح زیر است.
در الگوریتم YOLO سرعت Faster R-CNN خنده دار به نظر می رسد. علی فرهادی و جوزف ردمون ادعا کردند که در روش YOLO، هوش مصنوعی می تواند 91 فریم در ثانیه ویژگی های تصاویر را استخراج و طبقه بندی کند. انسان حتی الامکان در 30 فریم مشابه در یک ثانیه بتواند چند شی را پردازش کند. به عنوان آزمایش در یک تصویر 30 فریم، یک فریم به صورت جامپ از تصویر دیگر باشد، تنها چیزی که بیننده می تواند بگوید این است که چیزی اتفاق افتاده است و فقط می تواند تغییرات را بسنجد. این در حالیست که در همین لحظه ای که انسان نتوانستند درک کند چه شده است، YOLO می تواند بگوید یه چیزی را در چه جایی دیده است. رباتها با این امکان می توانند تصمیم های سریعتری که انسان اصلا متوجه آن نشده است، را بگیرد و از خطرهای قریب الوقوع اجتناب و یا جلوگیری کنند.